Introduction
GraphQL has been gaining a lot of traction with enterprises and startups for their application data layers. Historically, the web has been built using REST and SOAP APIs which have served their purpose successfully for years, but as applications have gotten more complicated and data has become richer, these solutions have created friction in developing performant software quickly.
In this article, we'll briefly discuss some of the problems with traditional API solutions, the benefits of migrating to GraphQL, and the strategy for migrating to a GraphQL solution.
Traditional API Problems
In traditional API systems, we typically suffer from a few common issues:
- Data under-fetching or n+1 fetching
- Data over-fetching
- All-or-nothing Responses
- Lack of batch support
Data Under-fetching
Traditional resources require us to request data on a per-entity basis, e.g. only users or only posts. For example, using REST, if we want to get some user details and their posts, we'd have to make the following requests:
GET /users/1GET /users/1/posts
Data Over-fetching
Conversely, when we request certain data, it will give us all the available information including data we might not care about. From our previous example, we might only want a user's name and username but the response might provide us their creation time and bio.
All-or-nothing Responses
However, if there's an error somewhere in this process, we might not get any data. Instead, we receive an HTTP status code informing us of a failure with an error message but none of the data that was fetchable.
Lack of Batch Support
Finally, for our more complex page, we might need to run multiple requests that can be parallelized but traditional APIs don't support this behavior out of the box. Dashboards, for example, might need sales and marketing data which will require our clients to make two separate requests to our server and wait on results before displaying that data causing perceived slowness in our application.
The GraphQL Advantage
Out of the box, GraphQL solves all of these described issues due to its declarative querying syntax and data handling. When you fetch data, you can request the exact data you need, and using the connection among entities, you can retrieve those relationships in a single request. If any of the data fails to fetch, GraphQL will still tell you about the data that was successfully retrieved and about the failures in fetching the other data, allowing you to show your users data regardless of failures. GraphQL also allows you to group multiple operations in a single request and fetch all data from a single request, thus reducing the number of round trips to your server and increasing perceived speed of your application.
In addition to these features, GraphQL creates a single gateway for your clients, reducing friction in team communication around how data should be fetched. Your API is now abstracted away behind a single endpoint that also provides documentation on how to use it.
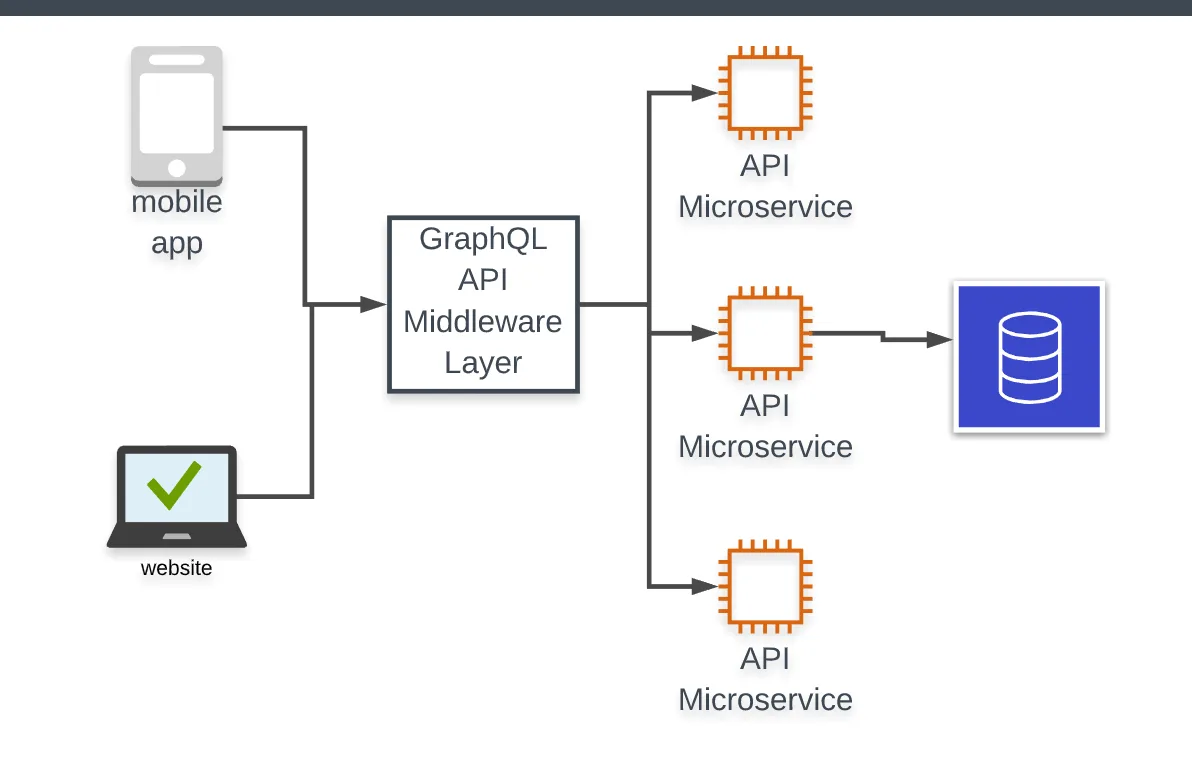
Given all these advantages, it's no wonder teams are moving to GraphQL, but it leaves the question of: how?
Migration Strategy
The GraphQL migration strategy is incremental so you don't have to slow down development to port over existing data or endpoints until you're ready to opt into those changes.
0. Before you begin
Before you start migration, here are some suggestions to think about as you're building new features or modifying the system in any way.
Don't build any new REST endpoints. Any new REST work is going to be additional GraphQL work later. Do yourself a favor and build it in GraphQL already.
Don't maintain your current REST endpoints. Porting REST endpoints to GraphQL is simple and GraphQL will provide you more functionality to build the exact behavior you want.
Leverage your existing REST endpoints to prototype quickly. You can use your existing REST API to power your GraphQL implementation. This won't be sustainable or performant long term, but it's a great way to get started.
1. Pick your GraphQL Implementation
Apollo and Relay are the two most popular fullstack GraphQL solutions, but you can also build your own solutions. Regardless of what you use, you'll use this to implement your server endpoint and connect to it with your client. All GraphQL requests go through a single endpoint, so once this is up and running, you can connect to it and begin porting functionality.
2. Select your first feature to build or port
With our server, we can start adding to it. Following our earlier example, let's migrate user posts.
3. Define your schema types
Now that we've decided on user posts, we have two routes here: (1) migrate users and posts or (2) migrate posts with a filter on user. For this, we're going to migrate posts and filter on user ID for now. To start, we'll define our post type in the schema and define its query type:
type Post {
id: ID!
userId: ID!
content: String!
}
type Query {
posts(userId: ID): [Post]
}
We now have a Post type that has an id and content and knows which user it belongs to. Additonally, we have a query called Posts that optionally accepts a userId as a filter and returns a list of Posts. It's important to note that it is semantically incorrect in GraphQL to expose the userId as a field. Instead, we should connect a post to its user and expose that entity relation, but those will be choices you make as you design your API.
4. Build our data resolver
Now, we need to connect our schema type and query to our data. For this, we'll use a resolver. The following syntax will vary slightly pending your server implementation, but using JavaScript and the GraphQL specification, we'd end up with the following resolver object:
const fetch = require('node-fetch');
export const resolvers = {
Query: {
posts: async (obj, args, context) => {
const { API_URL } = process.env;
const { userId } = args;
if (userId){
const response = await fetch (`${API_URL}/users/${userId}/posts`);
return await response.json();
}
const response = await fetch (`${API_URL}/posts`);
return await response.json();
},
}
};
If the userId is present in the query arguments, we use our existing REST API to fetch the posts by user, but if no userId is provided, we use the posts route directly. Now, we can make the following request on the frontend to retrieve our data:
query UserPosts($userId: ID!) {
posts(userId: $userId) {
id
content
}
}
I chose to use node-fetch for my implementation because it was simple, but you can use any HTTP library of your choice. However, if you're in the Apollo ecosystem, they've built a RESTDataSource library that will create an extension to your GraphQL implementation for handling resolvers to microservice APIs that can setup the boilerplate for that service so you only worry about fetching the data.
5. Next Steps
Extending Our Graph
Now that we have our data integrated, we need to complete the graph by connecting related types. Instead of Post having a userId, it can have a User and fetch the author details directly from the same query, e.g.
query UserPosts($userId: ID!) {
posts(userId: $userId) {
id
content
user {
id
avatarUrl
displayName
}
}
}
Monoliths
Because we now have queries and types with full control of our schema, we can update our resolver functionality to rely on the codebase and not our REST API abstraction which will give us some added perfromance benefits. We can keep stitching together new types and extend our API further.
Microservices
GraphQL and microservices go hand-in-hand pretty well. GraphQL supports schema stitching, which allows us to build individual GraphQL APIs in our microservices and then combine them to make up our larger interface. Now, instead of configuring our clients to define all the different connections to different services, our GraphQL server understands where to collect all the data from, simplifying the amount of information the frontend needs to know about in order to complete requests.
Performance
A major downside to GraphQL can be the server-side overfetching, or n+1 problem. Because GraphQL doesn't know exactly how data is structured in the database, it cannot optimize for redundant requests in the graph tree. However, the GraphQL DataLoader library is here to solve exactly that. It determines any data that's already been fetched and caches for use in any sub-query to follow.
Conclusion
With all this power, it's no wonder GraphQL is picking up so much steam in the community. That being said, GraphQL isn't for everyone or might not be a good solution for your team today. However, I would suspect lots of future APIs we rely upon will start utilizing GraphQL more heavily and we'll see a trend away from traditional REST. Hopefully, you've seen the opportunity of GraphQL in your codebase and how it will help your team deliver quality products faster, and you can have a conversation with your team about a possible migration.




