
Introduction
In 2023, Google announced the retirement of Universal Analytics and told everyone to migrate to Google Analytics 4, commonly known as GA4. Google Analytics has long been a staple for businesses and website owners seeking insights into their audience and performance metrics. However, with the introduction of Google Analytics 4, there comes a pivotal moment for users of the older Universal Analytics (UA) platform.
Difference between UA and GA4
What data will you lose?
You will lose ALL of the historical data! By July 1, 2024, Google will delete all UA data, and you will no longer have access to it after that. Also, Universal Analytics will no longer track new conversions, affecting ad campaign performance that relies on these conversions for Smart Bidding. Audience lists from Universal Analytics will also disappear, potentially impacting media activation and performance. API requests tied to Universal Analytics properties will fail, preventing data deletion requests and causing Looker Studio to stop displaying Universal Analytics data. Additionally, Attribution Projects (beta) in Google Analytics will be deleted.
How to Export Your Data
There are multiple ways to export your data from Google Analytics, such as using the Google Analytics add-on for Google Sheets or using BigQuery integration to export historical data from your Universal Analytics 360 property.
This article will discuss the easiest way to export your data using the Google Analytics add-on from Google Workspace Marketplace.

From “Extensions” > “Google Analytics” > “Create new report”
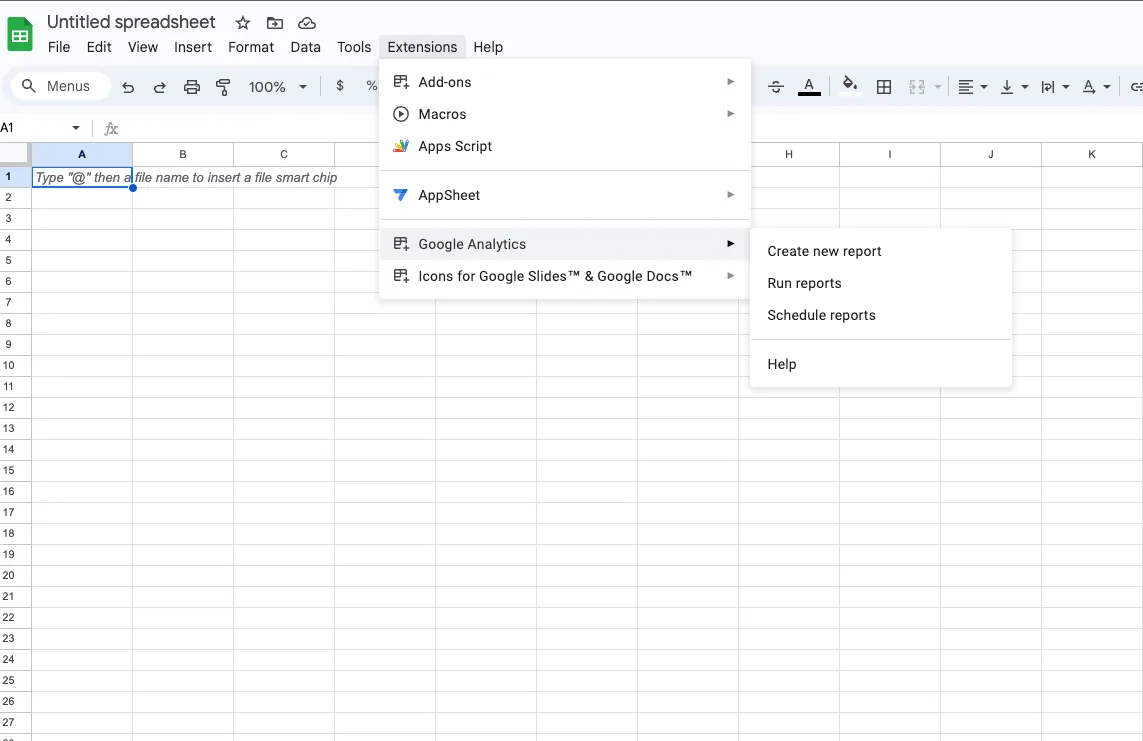
The Google Analytics extension will display a Wizard that requires the following steps:
- Set a name for your report
- Then, you select the Google Analytics account
- Then, the property you want to export
- Also, there are some optional configuration that helps you filter the data you want to export
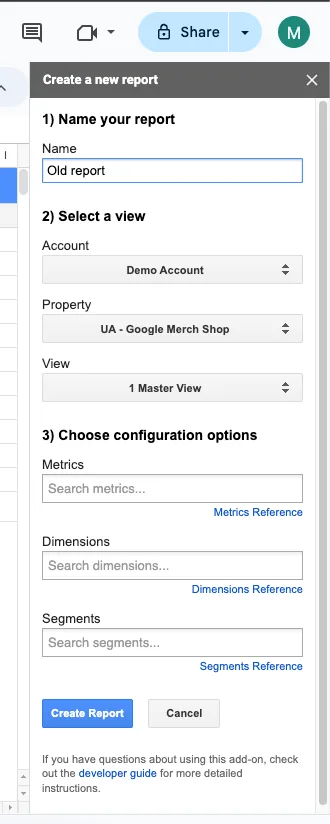
Then click on “Create Report,” and it will export the report for you
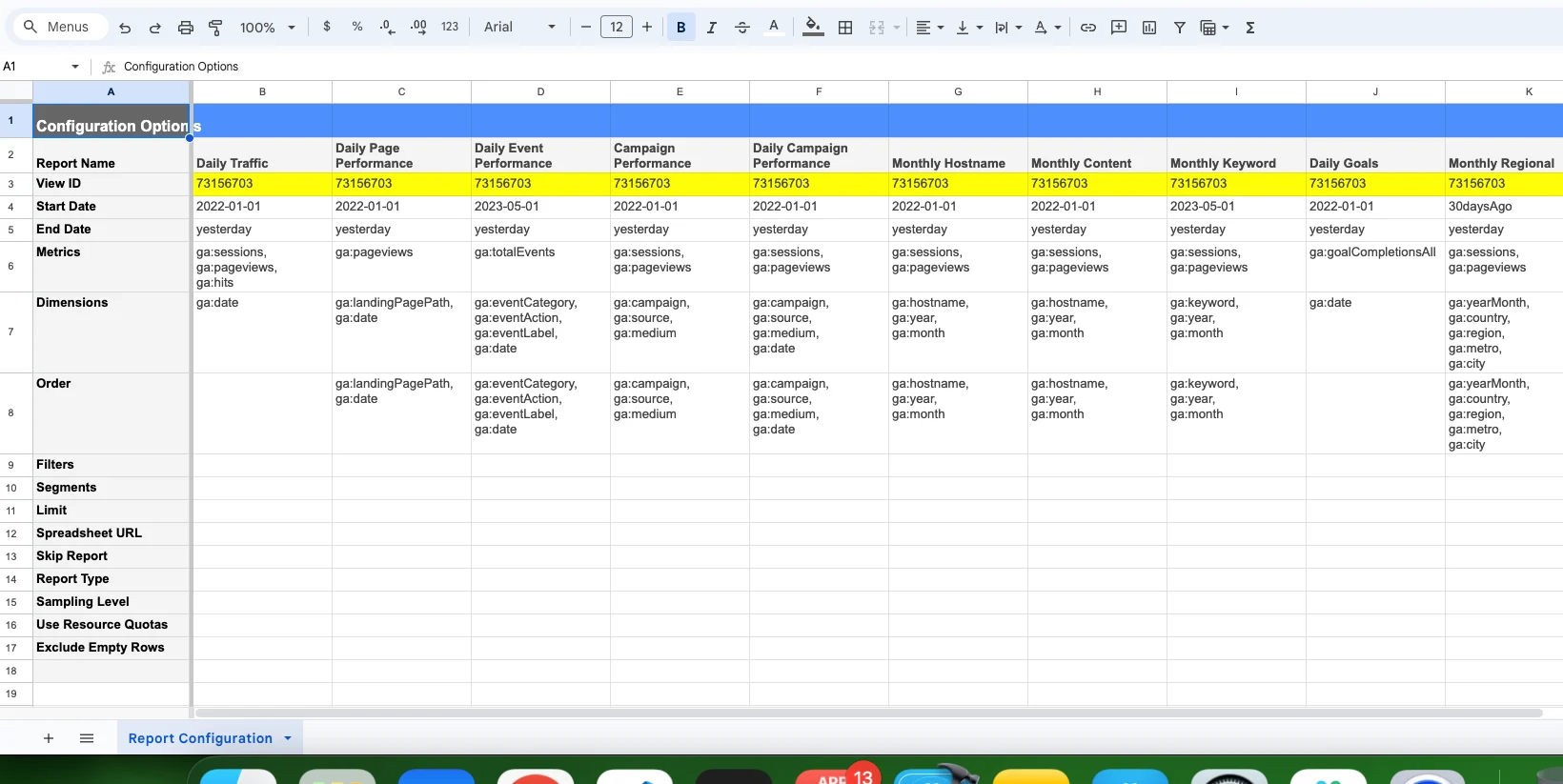
Here is an example of the template https://docs.google.com/spreadsheets/d/1zXEBEQQk6TPeGb7-Wm2J0uM0q0XnTdJqrfikCTmYs8c/copy
Running the Report
After setting up the report template with the necessary configurations, users can run the report to extract their UA data into Google Sheets. Depending on the size of the dataset, the report may take some time to generate, especially for larger datasets spanning multiple years. In such cases, splitting the data into smaller chunks may be necessary to ensure efficient processing.
Conclusion
As Google transitions from Universal Analytics to Google Analytics 4, businesses and website owners must proactively preserve their valuable historical data. With the impending deletion of all Universal Analytics data by July 1, 2024, failing to export your data in time could result in significant data loss, affecting ad campaign performance and analytics capabilities. By following the outlined methods to export data using tools like the Google Analytics add-on for Google Sheets, you can ensure that your historical data is safely archived and accessible for future analysis.




